ClickHouse学习
2021-06-06
- ClickHouse与Mysql或presto不同,是大小写敏感的。
- 有些关键字是不大小写敏感的,具体关键字的情况可以通过系统表system.data_type_families 查询了解。
- name (String) — 数据类型的名称.
- case_insensitive (UInt8) — 该属性显示是否可以在查询中以不区分大小写的方式使用数据类型名称。
- alias_to (String) — 名称为别名的数据类型名称。
SELECT * FROM system.data_type_families
- 在这举例一些常用不敏感关键字:
- DateTime、Date、Decimal、NVARCHAR、VARCHAR、CHAR、TIMESTAMP、INTEGER、INT、BOOLEAN、DOUBLE、BYTE
2. 查询使用(对比或新特性)
SELECT COLUMNS('a') FROM table
- 可用columns()语法来查询表中列名包含指定字段的数据
SELECT DISTINCT a FROM t1 ORDER BY b ASC
- ClickHouse支持使用 DISTINCT 和 ORDER BY 在一个查询中的不同的列。
- DISTINCT 子句在 ORDER BY 子句前被执行。
- 而prestosql或mysql都必须要求排序的字段必须包含在select子句中:

SELECT s, arr FROM arrays_test ARRAY JOIN arr
- ARRAY JOIN用于生成一个新表,该表具有包含该初始列中的每个单独数组元素的列,而其他列的值将被重复显示。
GROUP BY
- group by在CH中不能像mysql或prestosql中可以写‘group by 1,2,3’来表示根据第123列的字段来分组,必须以字段全称写入‘group by a,b,c’
Limit n,m
- ClickHouse允许选择个 m 从跳过第一个结果后的行 n 行
- 另外ClickHouse支持直接在同层级调用as所命为别名的函数,不需要再外层嵌套
Limit n by a / Limit n,m by a
- 与查询 LIMIT n BY expressions 子句选择第一个 n 每个不同值的行 expressions. (可理解成分组取有限值)例:
SELECT * FROM limit_by ORDER BY id, val LIMIT 2 BY id
- 在limit_by表中根据id字段取出每个ID的前二的数据(需用order by排序)
SELECT * FROM limit_by ORDER BY id, val LIMIT 1,2 BY id
- 在limit_by表中根据id字段取出每个ID的从1开始的往后的两份数据(不包含1),第一个例子等同于limit 0,2 by id
- 另外limit by跟limit属于不同的子句类型,在同一查询中可以同时使用
SELECT * FROM t_null_nan ORDER BY y NULLS FIRST
- CH可通过nulls first关键字让排序时null字段首先显示
SAMPLE k / SAMPLE n /SAMPLE k offset n
- 对数据进行采样,如sample 0.1为取样10%的数据,用于在数据量过大(内存不足)时通过较少的数据量来获得近似的数据查询结果,而当sample值大于1时,则是模拟大量的数据,来取一个近似值,如sample 100 则会将原先数据复制100倍,来通过较少的数据来获得大量数据的一个近似的数据查询结果。
- 通过sample k offset n子句,可以指定取样值在数据中的位置跟范围,如SAMPLE 1/10 OFFSET 1/2,表示从数据的后半部分取出10%的样本。
3.函数
toInt() / toFloat() / toDate() / toDecimal()
- ClickHouse支持在类型转换函数后增加OrZero/OrNull 子句来处理类型转换后失败的数据返回为0/null。
basename()
- 在最后一个斜杠或反斜杠后的字符串文本。 此函数通常用于从路径中提取文件名。如果输入的字符串中不包含斜杆或反斜杠,函数返回输入字符串本身。例如:
- SELECT 'some/long/path/to/file' AS a, basename(a) 结果为file
- SELECT 'somelongpatofile' AS a, basename(a) 结果为somelongpatofile
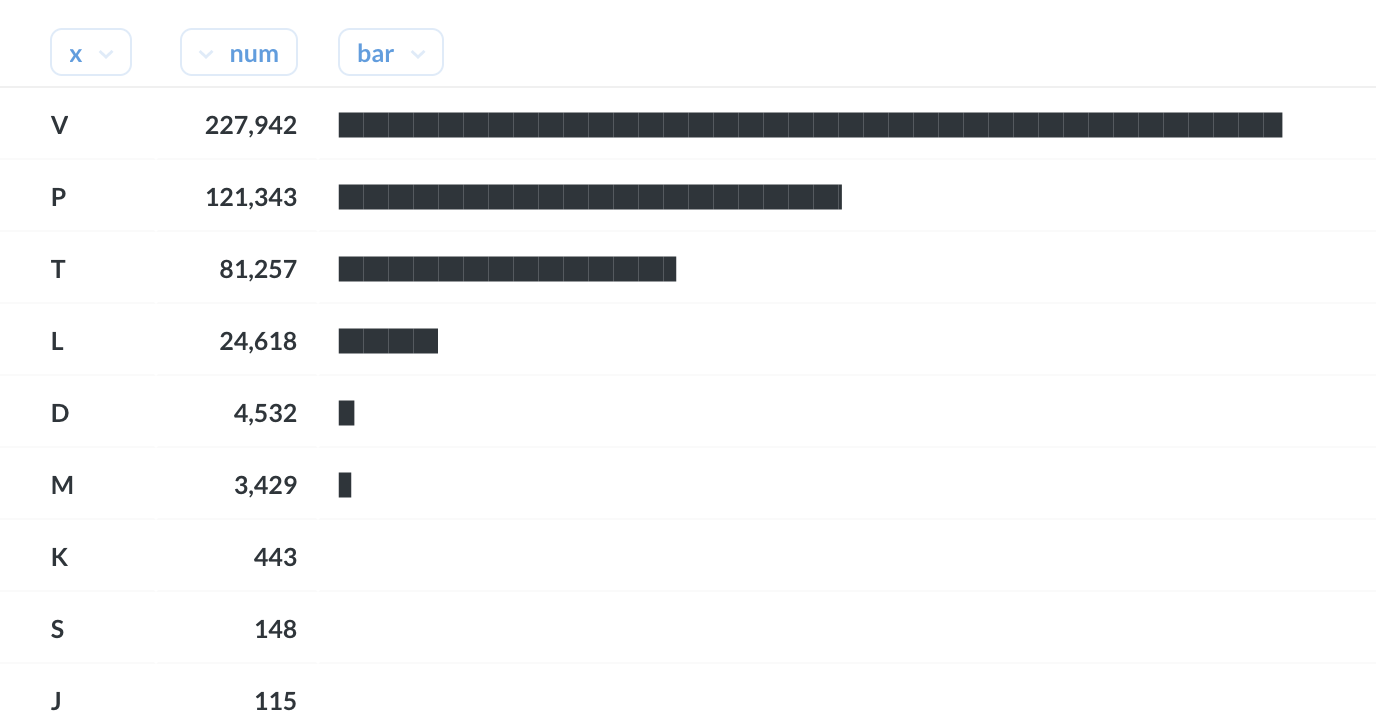
bar()
- bar(x, min, max, width) 当x = max时, 绘制一个宽度与(x - min)成正比且等于width的字符带。其中,x — 要显示的尺寸。
- min, max — 整数常量。
- width — 常量,可以是正整数或小数。(在matebase测试中最大值为1000)
- 例:
select substring(msn,1,1) as x,count(1) as num,bar(num,0,3000000,500) AS bar
from dwd.dwd_machine_app_state_info
where "date">'2021-05-01'
group by x
order by num desc
- 会根据每个x的记录数,产生根据记录数的字符带,(注:在这里因为app表中date字段跟CH中的不敏感关键字date重复,所以需要加上双引号进行处理,在prestosql中则不需要,在hive中则需要加上斜点
date进处理)从而直观的展示数据大小,结果:
floor(a, b) round(a,b)
- floor函数跟round函数都是取整函数,区别是round函数会有四舍五入的效果,此外CH的取整函数支持b为负数来取整,(当floor函数的b不填或为零时,默认为不进行取整,也就是原数据输出,而round函数b省略或为零时,则是默认取到整数),例:
- floor(123.45, 1) = 123.4, floor(123.45, -1) = 120.
- round(3.2, 0) = 3,round(4.1267, 2) = 4.13,round(22,-1) = 20
appendTrailingCharIfAbsent(s,c)
- 如果’s’字符串非空并且末尾不包含’c’字符,则将’c’字符附加到末尾。
endsWith(s,后缀)/startsWith(s,前缀)
- 返回是否以指定的后缀结尾/开头。如果字符串以指定的后缀结束/开头,则返回1,否则返回0。
trimLeft(s)/trimRight(s)/trimBoth(s)
- 返回一个字符串,用于删除左侧/右侧/全部的空白字符。
splitByChar(分隔符,s)/splitByString(分隔符,s)
- 通过分隔符将s字段拆分成多个子串,两个到区别在于splitByChar的分隔符必须是单字符,而splitByString的分隔符可以由多个字符组成
position(haystack, needle[, start_pos])
position(needle IN haystack)
locate(haystack, needle[, start_pos])
- 在haystack字段中寻找needle子字符串,返回位置,如果未找到子字符串,则为0(区分大小写,positionCaseInsensitive()函数不区分大小写,使用跟position一样)。例:
- SELECT position('Hello, world!', '!'); 结果为13